Copyright 2019-2024 微推堂 版權所有 京ICP備2019123967號
10 月 14 日消息,科技媒體 9to5Mac 今天(10 月 14 日)發布博文,報道稱蘋果提出 FS-DFM 擴散模型,僅需 8 輪快速迭代,即可生成與傳統模型上千輪迭代質量相媲美的文本,且寫入速度比同類模型最多可提高 128 倍。
蘋果公司與俄亥俄州立大學的研究團隊近期聯合發表論文,提出一種名為“少步離散流匹配”(Few-Step Discrete Flow-Matching,簡稱 FS-DFM)的新型語言模型。

該模型專注于解決長文本生成領域的效率瓶頸,僅需 8 輪快速精練,就能生成高質量的長篇文本,其效果足以媲美傳統擴散模型執行上千步迭代所實現的效果。

在深入了解 FS-DFM 之前,需要區分兩種主流的語言模型范式:
以 ChatGPT 為代表的自回歸模型,其工作方式是逐字(Token)串行生成文本,后一個字的生成依賴于前面所有內容。
而擴散模型則采用并行策略,一次性生成多個字,再通過多輪迭代逐步優化,直至形成完整的回應。
FS-DFM 作為擴散模型的一個變體,進一步簡化了迭代過程,旨在用最少的步驟直接生成最終結果。IT之家援引博文介紹,蘋果研究人員為實現這一突破,設計了一套精妙的三步法:
首先,模型經過專門訓練,能夠靈活適應不同的精煉迭代次數。
其次,團隊引入一個“教師”模型進行引導,確保模型在每輪迭代中都能進行大幅且精準的更新,同時避免出現“矯枉過正”的問題。
最后,他們還優化了迭代機制本身,讓模型能以更少、更穩健的步驟生成最終文本。
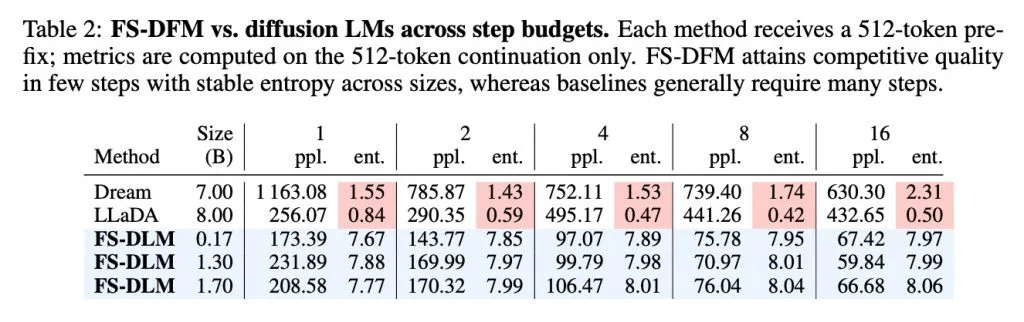
在性能評估中,FS-DFM 還支持對比了擁有 70 億參數的 Dream 模型和 80 億參數的 LLaDA 模型。測試結果顯示,即使是參數量僅為 1.7 億至 17 億的 FS-DFM 變體,在困惑度(衡量文本準確與流暢性的指標,越低越好)和熵(衡量模型選詞置信度的指標。熵太低,生成的文本可能單調重復;熵太高,則可能胡言亂語)兩項關鍵數據上,都表現出更低的困惑度和更穩定的熵。